



Before we go deeper into the exciting topic of AI, let’s first answer one burning question — what’s behind all the excitement and hype?
Long before Gen AI became such a hot topic, many analytical organizations were highlighting the importance of automation and its huge potential to help the business. Reports like “Will robots really steal our jobs?” by PwC, “Augmentation through automation” by Deloitte, and “Automation is Back with a Bang!” from HfS Surve foresaw remarkable improvements in business outcomes (up to 73%) and huge cost savings through automation. They argue that automation could reduce labor expenses by up to 45% and could lead to an astonishing 90-95% reduction in errors compared to manual processes.
Now, with the power of OpenAI ChatGPT, Google Bard, and other Large Language Models (LLM), the future of automation seems even more promising.
It sounds like AI is a game changer and will skyrocket our business, but is everything as rosy as it seems, or are there potential pitfalls we should think about? Have we discovered the Holy Grail, or are there unexpected consequences to be aware of?
In this article, we will explore the realities of Gen AI and address the following key aspects:
- The importance of governance for AI and why it’s essential
- Responsibility for the consequences of decisions made based on AI-generated data
- The optimal time for implementing AI governance measures
- Establishment of governance processes to effectively manage AI throughout its lifecycle
The importance of governance for AI and why it’s essential
In the world of AI, the answers are generated based on the data fed into it. Hence, it’s obvious that the quality and integrity of the data used to train the AI model is a vital factor. As well as the policies and standards applied to this data.
If the data fed to the AI model is bad, it can lead to catastrophic consequences. For instance in the scenario when an AI model is trained on data generated by another AI model. In such cases, the AI model loses all meaning, giving greater importance to higher-probability outcomes and decreasing or even eliminating improbable events, nullifying the model’s original data distribution and intent. So eventually such a model will become useless.
A good example of the unexpected AI model degradation is OpenAI’s language model, ChatGPT. All OpenAI’s models are continuously updated, they are not static technologies, and recently, users of the GPT-4 which is the latest version of the model noticed that response quality has dropped significantly. For instance, the accuracy of the answer to the question “Is this a prime number?” fell from 97.6% to 2.4% from March to June.
In code generation, where directly executable code is important, the researchers discovered significant performance changes for the worse. The percentage of directly executable code generated by GPT-4 dropped from 52.0% in March to 10.0% in June. GPT-3.5 also experienced a large drop from 22.0% to 2.0%. Additionally, the verbosity of GPT-4 increased by 20%.
This is why the processes that will help us to ensure model assessment/benchmarking are critical for every LLM. They will help us to identify potential issues and facilitate quick, corrective actions when needed. Additionally, users of the model should have the ability to report any detected problems such as biased results, policy violations, wrong answers, performance issues, etc. And there should be people assigned to the model, taking responsibility for resolving these issues in accordance with predefined processes.
This reminds us that we cannot rely on the AI model entirely. All organizations should use a “Human-in-the-Loop” approach, where individuals thoroughly double-check and validate the results generated by the model before using them in business processes or making business decisions based on them. This human intervention ensures accuracy and mitigates any potential risks associated with complete reliance on AI-generated outputs.
Responsibility for the consequences of decisions made based on AI-generated data
AI becomes a part of many areas of our life, and one of the most noticeable examples is self-driving cars. Interestingly, the concept of autopilot dates back much further than one might imagine, with its first deployment more than a hundred years ago in 1912 by Sperry Corporation for aircraft. The automatic flight control system that Sperry called an “autopilot” was pretty simple and could manipulate the flight controls to correct an aircraft’s heading based on deviations detected with the gyro-compass and an automated link between the heading and altitude information. Many years after that, with AI, the autopilot has truly become intelligent and accessible to people without requiring extensive training or preparation. Today, we see more and more car companies adding autopilot in their cars which is really awesome.
At the same time, there is a growing concern over the distressing news about car incidents involving vehicles in ‘full self-driving’ mode . As the number of such incidents increases, each case is carefully investigated so as to understand the root cause and identify measures to prevent future accidents. And of course, questions arise about the true responsibility – is it the car, the driver, or the government that permits their operation on the roads?
However, the situation is more complex, as responsibility cannot be solely assigned to one party. Instead, accountability is distributed among three main entities:
- Car manufacturers: They are accountable for the design, programming, and functionality of the self-driving system. They have to follow safety standards and ethics while continuously improving the technology
- Drivers: They are responsible for continuously monitoring the vehicle’s operations and intervening if required. On top of that, drivers have to be informed about their roles in autonomous driving scenarios and trained if necessary
- Regulators: They are responsible for establishing safety standards and aligning clear guidelines and regulations governing the use of self-driving cars on the roads, and defining the legal responsibilities of each party involved
Incorporating a model with a well-defined distribution of responsibilities ensures that all parties involved understand and accept the consequences of potential errors and take proactive measures to mitigate their impact.
Now, let’s go back to the implementation of AI in our business and address a similar question: If a business decision is made based on AI-generated data, resulting in significant financial losses (in the millions of dollars), who will hold the accountability?
In this scenario, we will also be discussing a distributed accountability framework, emphasizing a shared responsibility approach that fosters collaboration among model providers, decision makers, and regulators that will bring transparency to the decision-making process among all stakeholders to minimize risks.
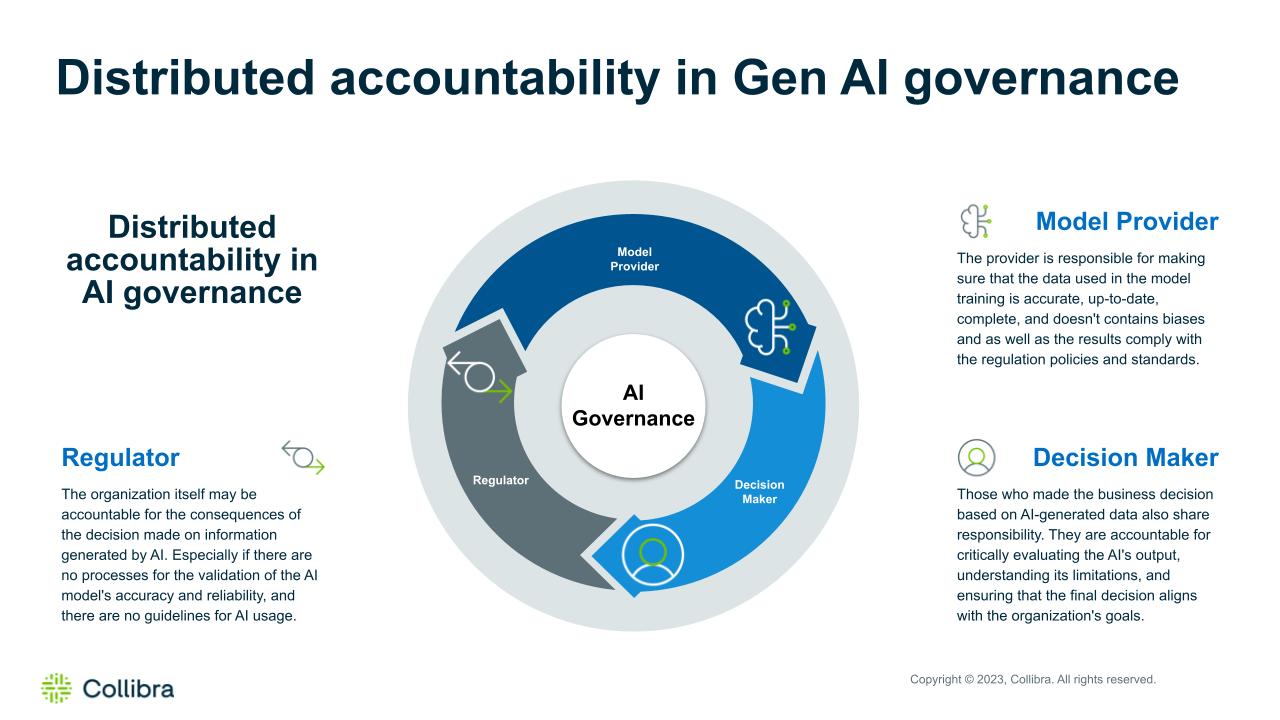
This approach empowers the organization to deliver the full potential of AI while maintaining a strong focus on risk management and responsible decision-making.
The optimal time for implementing AI governance measures
With a clear understanding of potential pitfalls and shared responsibilities among the involved parties, the next critical question will be — how can we effectively mitigate these potential risks? Proactively addressing these known challenges becomes essential to ensure that in an attempt to use the enormous potential of Generative AI for good, we won’t make any fatal mistakes.
So there need to be guardrails implemented to establish the balance between embracing AI’s capabilities and protecting the business from the potential consequences of misusing the AI.
Every organization takes the responsibility of establishing policies and rules that serve as guidelines for AI usage. However, it’s crucial for these guidelines to be adopted by decision-makers. Simply having rules in place is not sufficient; ensuring that people are aware of them and adhere to them requires training, education, and regular audits.
If decision-makers lack proper training or understanding of these rules on how the AI models work, the organization must review its training and education programs to ensure they are competent in utilizing AI-generated insights effectively.
It is the organization’s responsibility to foster a culture of accountability within the company, encouraging open discussions about data-driven decisions and creating an environment where errors are acknowledged and serve as learning opportunities.
The fact is that there are many different LLMs and only one of them, ChatGPT, in April already had 1,8 billion visits per month. Millions of people already use the LLM on a daily basis and we can only assume how they use the generated results for their day-to-day work activities.
It means that quick implementation of the measures is absolutely critical. And doing so we will significantly reduce risks for our business. The earlier we take action, the safer our AI journey will be.
Establishment of governance processes to effectively manage AI throughout its lifecycle
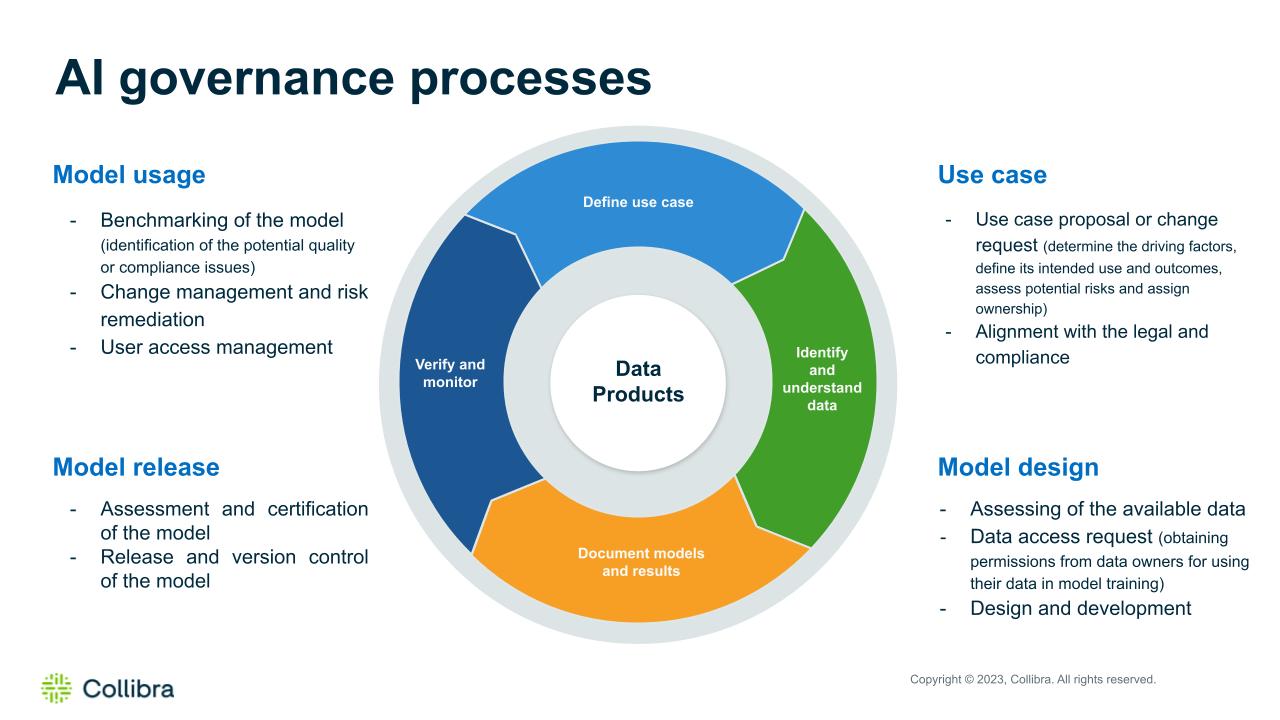
Going back to the car analogy, even the most advanced self-driving cars today still rely heavily on human intervention throughout their production, maintenance, service, and usage (at least for now). And this is the case for LLM as well. Throughout the entire lifecycle of LLM, a lot of processes will require us to establish governance procedures, with clear roles and responsibilities that will be defined and assigned to people.
These processes will help us to control the training procedure so as to ensure compliance with the regulation policies and protect our model from collapse. It will also ensure its evolution and the right usage according to the defined guardrails.
While the training process can be significantly automated, it still heavily relies on human decisions regarding what data will be fed into the model. And the quality of these decisions will depend on the data scientist’s comprehensive understanding of the existing data.
However, during the training process, some organizations may encounter a significant challenge. Although they have access to millions of data points that could potentially be used for model training, the absence of the context around this data makes it quite difficult to decide which data is appropriate for the training.
Understanding the meaning of the data, its quality, primary data source, owners, presence of intellectual property (IP), the sensitivity of the data such as PII, and other vital aspects of the data is absolutely crucial. Only by having this information will we be able to effectively and securely train the model and also comply with the AI Act regulation that is coming next year.
The challenge here is that adding this context is not automatic. It will take a lot of effort to review the gathered data, confirm the identified classes, enrich this data, connect with each other etc.
Another critical aspect to consider is that the data our organization would like to use for training may belong to someone else. And before feeding this data to the model you will need to get the data usage permission from the rightful owner. Skipping this important step could lead to potential legal issues for the organization in the future. Hence, we will need a governance process to facilitate collaboration with data owners during the model training phase.
And of course, at the end of the day, there should be a process to manage the user access to the models and their results. Depending on the roles, geography, business division, access permissions, etc. users may receive varying results from the same model. Users should provide information about why and how they will be using the model in their job, and also agree to the policies of usage, data-sharing agreements, and other relevant terms before they will get the access to the model. Each user should receive appropriate access that aligns with organizational requirements.
The future of AI
It’s already obvious that AI will revolutionize how we do business and handle data, streamlining existing business processes and automating various activities. However, what also remains clear — human intervention remains absolutely critical and unavoidable.
It will always be a human who will be ensuring model accuracy and ethical considerations, and who will make the final decision regarding when and how the AI should be used.
P.S. When I was writing this article I thought about Alan Turing who once said “We may hope that machines will eventually compete with men in all purely intellectual fields,” and also HAL 9000 and its famous “I’m sorry, Dave. I’m afraid I can’t do that.” I don’t know where AI will lead us but it will be an interesting journey for sure.


