



Having spent time leading IT Operations, I enjoy hearing data leaders discuss trending data topics, be it data mesh or in this blog’s case, data observability. Oftentimes, the concept seems new, as it is new to the data world. Still, like most concepts and architectures, they tend to have deep roots within the CIO organization, and that background helps support greater understanding.
How did we get here? What is Data Observability?
Before Data Observability, there was IT Observability. IT Observability represents an evolution of IT Logging and Monitoring – a technical solution that supports the triaging, not just identifying or quantifying. In keeping with helping broaden our understanding, we may want to break the topics out.

- Logging. Think of this like raw application data. Continuous delivery methodology dictates we should track the data of applications and manage it. This method led to a slew of best practices, including things like the very existence of logs. Today, it’s pretty standard for applications to produce the output of what they are doing, not just doing the function, which was not always the case.
- Monitoring. Consider this as applied logging, leveraging that raw application data for verifying application performance via metrics. It organizes a predefined set of those logs to baseline a status quo or “are my systems functioning?” Monitoring brought forth some of the more commonly known applications, like Dynatrace.
- Now – Observability. I like the Google definition which states that “Observability is tooling or a technical solution that allows teams to actively debug their system. Observability is based on exploring properties and patterns not defined in advance”. Encompassing traces in addition to metrics and logs, observability is effectively taking reactive monitoring and adding the layer of proactive insight. To make it tangible, observability is typically executed with tools like Splunk and DataDog.
So, for Data Observability, we see that the same IT Observability that exists throughout software systems has spread into data systems. Data Observability is focused on the impact of production-grade data on its consumers. How we see data functionality is the same as any application, with expectations on output. The same frustration that would occur with your “email not sending,” occurs when your “data is incorrect.”
How do we quantify Data Observability?
Retracing our roots to IT Observability, those metrics may be focused on uptime and downtime. They have key items like RTO (recovery time objective) and RPO (recovery point objective).
RPO may very well be a good metric for Data Observability. However, as industry leaders, we are hearing – measure Data Observability to the concept of data downtime. Data downtime refers to periods of time when your data is partial, erroneous, missing, or otherwise inaccurate.
I would argue that while the cost of data downtime is just as impactful as any downed application in IT, there is a stronger prevention model in the software delivery lifecycle. All software undergoes rigorous testing in “lower” environments with User Acceptance Tests, and quality software that doesn’t necessarily sit in the quadrant for IT observability, for example, a tool like Cucumber for developer testing.
But data is always in a production state. Think about the challenges of controlling data quality, given that the creation mechanism is not exactly SDLC (Software Development Life Cycle). One could apply SDLC-like testing measures, for example, a lower environment stress test before data migration. But it is often skipped and is only a half-measure compared to the quality control in SDLC for Application Development.
Further, one could have endured Priority 1 (P1) impact data downtime and not know it. For context, a P1 ticket for production-grade software typically means a lot of people are screaming, “trades are not working” or “email is down” But for data, bad data quality could be a sleeper problem that only manifests after business decisions are made.
So like IT Observability, business cares when data is down, but it is not the easiest alert mechanism. This makes it much harder to prioritize. Two decades into our industry, we find data downtime is a need falling into prioritization ambiguity.
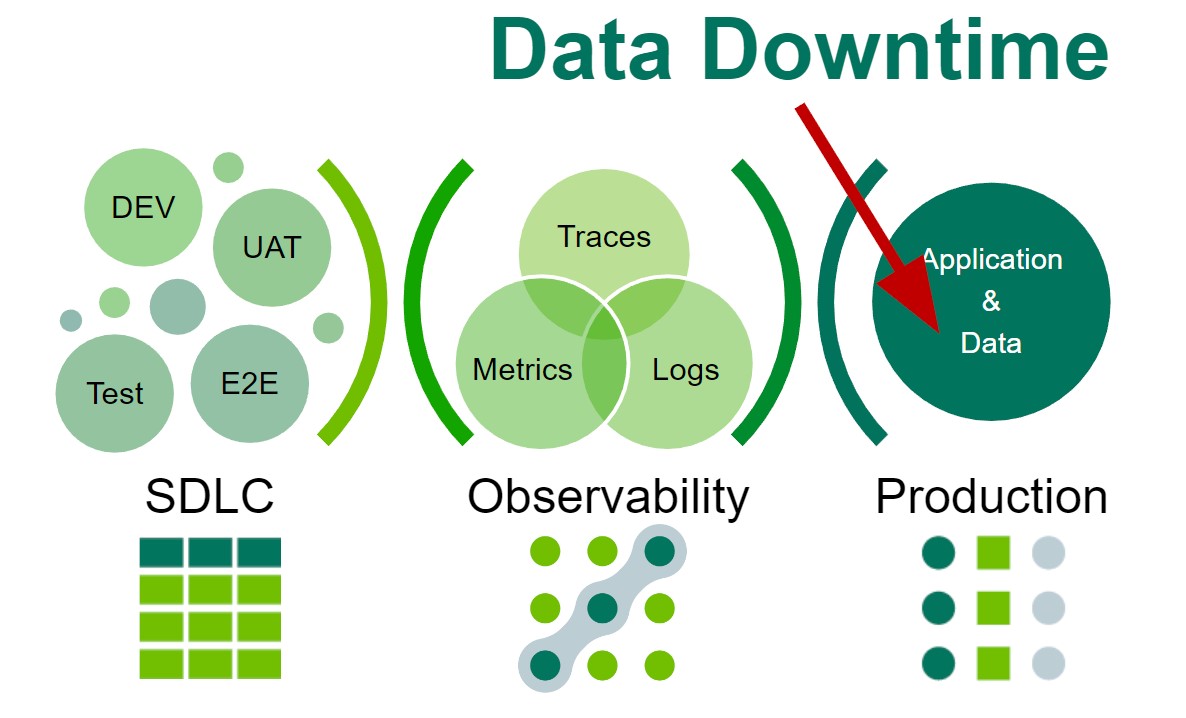
Who helps us avoid data downtime?
The most recent term for teams involved in IT Observability is DevSecOps. In keeping with the nomenclature around operations, one might call this persona DataOps. And to qualify this term, just like DevOps or SecOps, DataOps personas represent that same focus of the software development lifecycle in alignment with business operations. We may call it the data development lifecycle. In short, they are the team fighting against data downtime.
This persona could encompass a series of more traditional roles based on the expertise required, as we would see in DevSecOps.
There is a Data User, this persona represents the L0 of data downtime. They see the data is wrong and escalate. Then there is a Data Operator, this could be the persona in the DataOps teams, an L1/L2 support capacity helping decrease data downtime and get systems back up.
But the primary persona in data operations is the Data Engineer. This persona not only represents the L3/L4 of a data lifecycle but also helps build the data pipeline and infrastructure around the data operations. Akin to Site Reliability Engineers, this persona is going to have the biggest stake in avoiding data downtime either in prevention or resolution. This persona values Data Observability the most.
“DataOps bridges data producers & consumers. It’s a set of practices & technologies to build data products and operationalize data management to improve quality, speed, and collaboration and promote a culture of continuous improvement.”
– Sanjeev Mohan, Principal, SanjMo & Former Gartner Research VP, Big Data and Advanced Analytics
So how should we work towards better Data Observability?
It is worth keeping an eye on IT Observability trends. If the CIO finds a new philosophy helpful for their software engineers, then chances are data engineers may also value it. In the CIO organization, I see observability boiling down to two translatable trends.
- We see a deep integration into CI/CD. The fact remains that new code merges are by far the most frequent sources of trouble. A new code merge creates a defect that brings application downtime, so the stronger the CI/CD upfront with pre-production testing, the less likely the application will be down into production. This fact is bolstered by the trend of observability tools to integrate into code, not just logs, helping trace the cause of the issue to the problematic code.
To relate to Data Observability, consider the integration into data pipelines. It’s likely the new data ETL is causing the latest data quality issue. The tighter the integration of a data observability solution into your data pipeline, the better one can see the issue at the point of break – helping trace the cause of data downtime to the problematic ETL.
- Second trend is the end-to-end unification of the technological “stack.” In addition to identifying and helping triage downtime to an application, one can help navigate that downtime across applications deep into the infrastructure. When someone or some monitoring system says, “My Tableau is not working,” observability streamlines the triage to help find the root cause that Tableau is working fine, but the Salesforce source is down.
To apply to Data Observability, consider Data Lineage. The better we can integrate the results into the lineage, the better we help reduce triage amidst data downtime – ultimately helping prevent additional issues in the future.
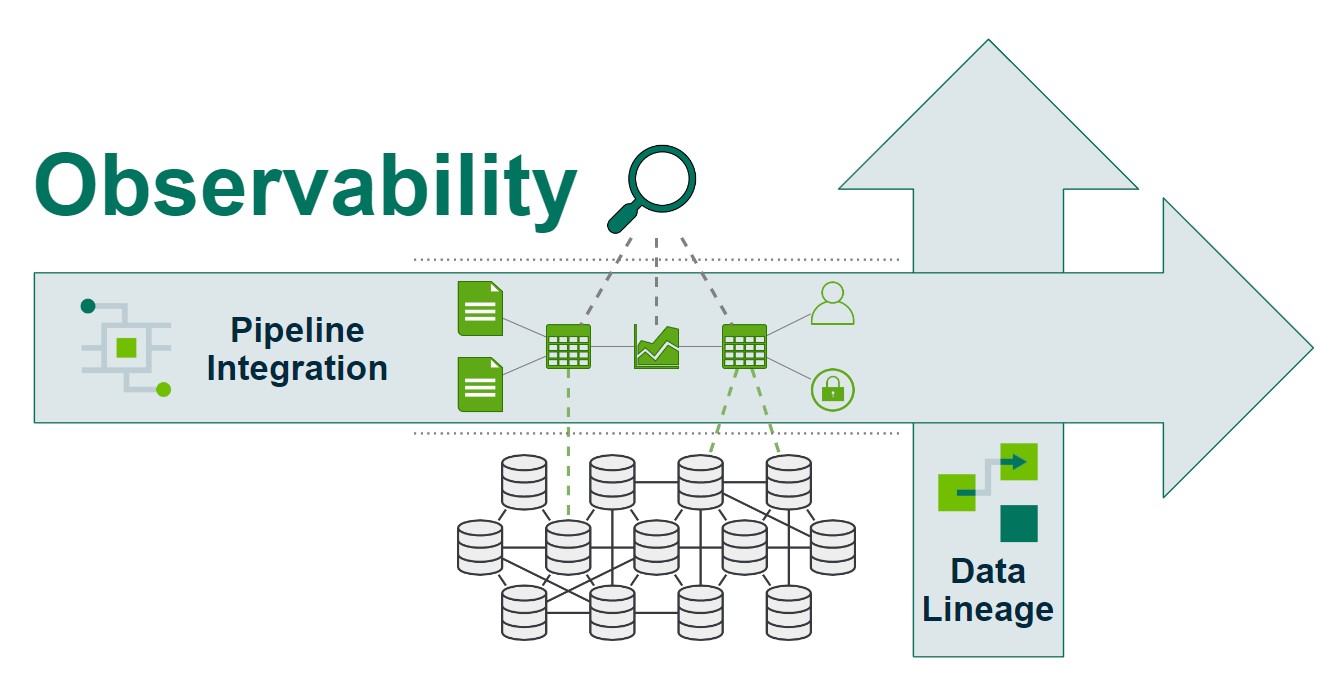
So what is the future of Data Observability?
Regardless of where the solution trends, I am optimistic about the prioritization of Data Observability. It feels like the mantra today is “every company is a software company” making observability valuable as a way to keep track of that software. In that same vein, we are hearing “every company is becoming a data company” which then would also trend towards Data Observability.
Bottom line, Data Observability is here to stay, and it’s time we make it an essential component of the technology stack.


